Python爬虫
笔记参考自视频连接:https://www.bilibili.com/video/BV1i54y1h75W?p=16&share_source=copy_web
一、第一个爬虫小程序
from urllib.request import urlopen
url = 'http://www.baidu.com'
resp = urlopen(url) # 打开网址
with open('baidu.html','w',encoding='utf-8') as f:
f.write(resp.read().decode('utf-8')) # 将网页源代码写入到文件
print('写入完成!')
- 爬取百度源代码并保存到本地。
二、web请求过程分析
服务器渲染:在服务器那边直接把数据和html整合在一起。统一返回给浏览器
- 在页面源代码中能看到数据
客户端渲染:第一次请求只要一个html骨架,第二次请求拿到数据,进行数据展示。
- 在页面源代码中,看不到数据
熟练使用抓包工具
三、HTTP协议

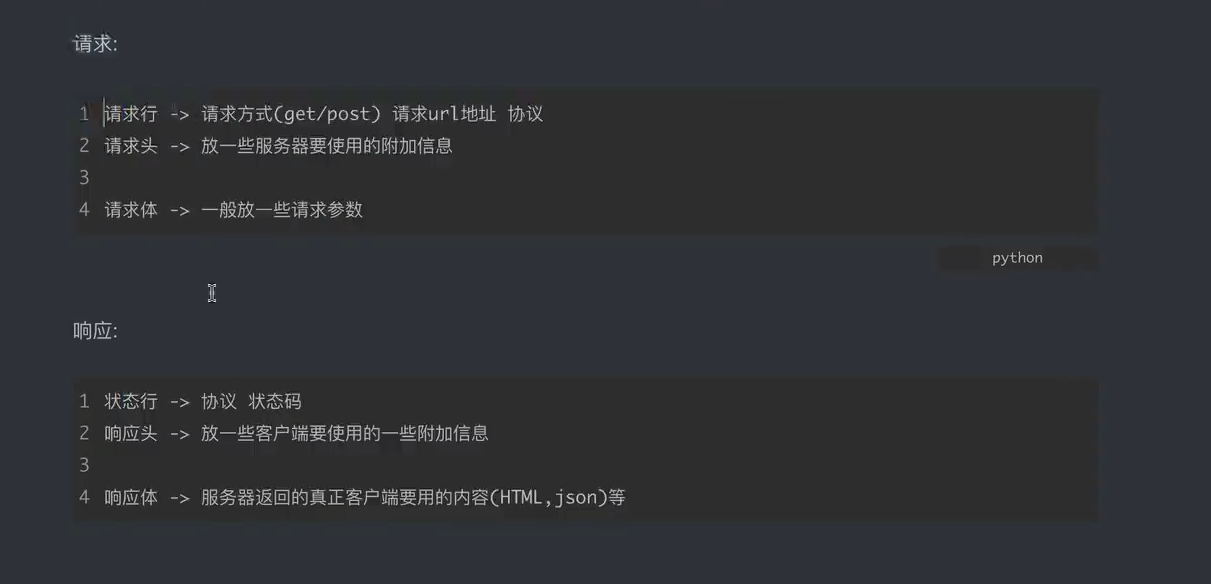

请求方式:
GET:显示提交
POST:隐示提交
四、requests模块
- 第一个爬虫
# -*- coding = utf-8 -*-
# @Time : 2021/6/6 19:46
# @File : 1.第一个爬虫程序.py
# @Software: PyCharm
from urllib.request import urlopen
url = 'http://www.baidu.com'
resp = urlopen(url) # 打开网址
with open('baidu.html','w',encoding='utf-8') as f:
f.write(resp.read().decode('utf-8')) # 将网页源代码写入到文件
print('写入完成!')
requests模块入门1
import requests query = input('请输入你想搜索的明星:') url = f'https://www.sogou.com/web?query={query}' # 要爬取的网址 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36' } # UA伪装 resp = requests.get(url,headers=headers) # 发送get请求,指定url和heards print(resp.text) # 获取页面源代码requests模块入门2
# -*- coding = utf-8 -*- # @Time : 2021/6/6 21:49 # @File : 3.requests模块1.py # @Software: PyCharm import requests url = 'https://fanyi.baidu.com/sug' s = input('请输入你要翻译的英文单词:') dat = { 'kw': s } headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/90.0.4430.212 Safari/537.36 ' } # 发送post请求 resp = requests.post(url, data=dat, headers=headers) # 写入设置 json = resp.json() # 打印获取到的代码转成json格式 print(json['data'][0]['v'].split(';')[0].split('.')[-1]) # 切片获取我们想获取的东西requests模块入门3
# -*- coding = utf-8 -*- # @Time : 2021/6/7 16:43 # @File : 4.requests模块2.py # @Software: PyCharm import requests url = 'https://movie.douban.com/j/chart/top_list' heard = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36' } param = { 'type': '24', 'interval_id': '100:90', 'action': '', 'start': 0, 'limit': 1 } # 指定参数 resp = requests.get(url=url,params=param,headers=heard) # 访问网页 body=resp.json() # 获取网页json格式数据 print(body) print('='*50) print(body[0]['title']) resp.close() # 关闭连接
五、数据解析
https://cdn.jsdelivr.net/gh/zhaotaogit/images/Blog_img/image-20210607170818247.png
1.re解析-正则表达式

元字符
元字符匹配内容. 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线 \s 匹配任意的空白符 \d 匹配数字 \n 匹配一个换行符 \t 匹配一个制表符 \b 匹配一个单词的结尾 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \W 匹配非字母或数字或下划线\D 匹配非数字\S 匹配非空白符a|b 匹配字符a或字符b() 匹配括号内的表达式,也表示一个组[…] 匹配字符组中的字符[^…] 匹配除了字符组中字符的所有字符量词
量词用法说明* 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次 贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
正则 |
说明 |
|---|---|
| .* | 默认为贪婪匹配模式,会匹配尽量长的字符串 |
| .*? | 加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串 |
1.1、re模块的使用
安装模块:pip install requests
1.2.re模块的匹配使用
# -*- coding = utf-8 -*-
# @Time : 2021/6/7 17:49
# @File : 5.re模块.py
# @Software: PyCharm
import re
# findall 匹配字符串中所有符合正则表达式的内容
# r防止转义
lst = re.findall(r'\d+','我的电话是10086,你的电话号码是10010')
print(lst)
print(type(lst))
print('='*50)
# finditer 匹配字符串中所有符合正则表达式的内容,返回结果是迭代器,从迭代器中获取内容需要group()
lst = re.finditer(r'\d+','我的电话是10086,你的电话号码是10010')
print(lst)
print(type(lst))
for i in lst:
print(i.group())
print('='*50)
# search 匹配字符串中所有符合正则表达式的内容,返回结果是match对象,获取数据需要group(),找到一个结果就返回
lst = re.search(r'\d+','我的电话是10086,你的电话号码是10010')
print(lst)
print(type(lst))
print(lst.group())
print('='*50)
# match 从头开始匹配,匹配到一个就返回
lst = re.match(r'\d+','10086,你的电话号码是10010')
print(lst)
print(type(lst))
print(lst.group())
print('='*50)
# 预加载正则表达式,多个地方可以使用
obj = re.compile(r'\d+')
lst = obj.findall('10086,你的电话号码是10010')
print(lst)
1.3.re模块匹配想要的东西并输出
# -*- coding = utf-8 -*-
# @Time : 2021/6/7 18:07
# @File : 6.re模块1.py
# @Software: PyCharm
import re
s ='''
<div class='jay'><span id='1'>郭麒麟</span></div>
<div class='jj'><span id='2'>宋铁</span></div>
<div class='jolin'><span id='3'>大聪明</span></div>
<div class='sylar'><span id='4'>范思哲</span></div>
<div class='tory'><span id='5'>胡说八道</span></div>
'''
obj=re.compile(r"<div class='.*?'><span id='\d+'>.*?</span></div>",re.S)
ret = obj.finditer(s)
for i in ret:
print(i.group())
print('='*50)
# (?P<分组名字>正则) 可以单独从正则匹配的内容中进一步提取内容
obj=re.compile(r"<div class='.*?'><span id='(?P<id>\d+)'>(?P<wahaha>.*?)</span></div>",re.S)
ret = obj.finditer(s)
for i in ret:
print(i.group('wahaha'))
print(i.group('id'))
1.4.re模块爬取豆瓣排行榜250信息
# -*- coding = utf-8 -*-
# @Time : 2021/6/7 18:38
# @File : 7.re模块2.py
# @Software: PyCharm
import requests
import re
import pandas as pd
# url = f'https://movie.douban.com/top250'
#
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
# }
#
# resp = requests.get(url=url, headers=headers)
# body = resp.text
# print(body.text)
# obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
# r'</span>.*?<p class="">.*?导演: (?P<director_zh>.*?) (?P<director_en>[a-zA-Z].*?[a-zA-Z]) .*?主演: (?P<Starring>.*?)/.*?<br>.*?(?P<year>.*?) ', re.S)
# result = obj.finditer(body)
# s=0
# for i in result:
# print(i.group('name'),i.group('director_zh').strip(),i.group('director_en').strip(),i.group('Starring').strip(),i.group('year').strip(),sep='\t\t')
# s+=1
# print(s)x
# for i in result:
# print(i.group('director_en'))
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?导演:(?P<director>.*?) .*?主演: (?P<Starring>.*?).{2,4}<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)'
r'</span>.*?<span>(?P<num>.*?)人评价.*?</span>', re.S)
# result = obj.finditer(body)
# dit = {'名称': [], '年份': [], '评分': [], '评价人数': [], }
# for i in result:
# dit['名称'].append(i.group('name'))
# dit['年份'].append(i.group('year').strip())
# dit['评分'].append(i.group('score'))
# dit['评价人数'].append(i.group('num'))
# dit = i.groupdict()
# dit['year'] = dit['year'].strip()
# print(dit)
# print(dit)
# data = pd.DataFrame(dit).drop([])
# print(data)
# data.to_csv('db.csv',index=False,encoding='gbk')
# resp.close()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
dit = {'名称': [], '导演': [], '主演': [], '年份': [], '评分': [], '评价人数': [], }
start = 0
for i in range(1, 11):
url = f'https://movie.douban.com/top250?start={start}&filter='
resp = requests.get(url=url, headers=headers)
body = resp.text
result = obj.finditer(body)
for j in result:
dit['名称'].append(j.group('name'))
dit['导演'].append(j.group('director'))
dit['主演'].append(j.group('Starring'))
dit['年份'].append(j.group('year').strip())
dit['评分'].append(j.group('score'))
dit['评价人数'].append(j.group('num'))
start += 25
resp.close()
data = pd.DataFrame(dit)
data.to_csv('db_all-250.csv',encoding='utf-8-sig') # utf-8-sig保证保存的csv不乱吗
print('over')
1.5.re模块爬取电影天堂信息
# -*- coding = utf-8 -*-
# @Time : 2021/6/7 21:22
# @File : 8.re模块3.py
# @Software: PyCharm
import requests
import re
import pandas as pd
domain = 'https://www.dy2018.com'
headers = {
}
obj1 = re.compile(r"021必看热片.*?<ul>(?P<inner_url>.*?)</ul>", re.S)
obj2 = re.compile(r"<li><a href='(?P<inner>.*?)'", re.S)
obj3 = re.compile('◎片 名 (?P<name>.*?)(<br />|</p>).*?代(?P<year>.*?)(<br />|</p>).*?地(?P<address>.*?)(<br />|</p>).*?别(?P<category>.*?)(<br />|</p>)'
'.*?言(?P<lang>.*?)(<br />|</p>).*?幕(?P<subtitle>.*?)(<br />|</p>).*?期(?P<time>.*?)(<br />|</p>).*?豆瓣评分(?P<db_score>.*?)(<br />|</p>).*?寸(?P<size>.*?)(<br />|</p>)'
'.*?小(?P<pang_size>.*?)(<br />|</p>).*?长(?P<long>.*?)(<br />|</p>).*?演(?P<director>.*?)(<br />|</p>).*?<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<url>.*?)">',
re.S)
resp = requests.get(url=domain) # verify=False去掉安全验证
resp.encoding = 'gb2312' # 指定编码
result = obj1.finditer(resp.text)
resp.close()
result = result.__next__().group('inner_url')
result = obj2.finditer(result)
url1 = [] # 存放子链接
dit = {'片名': [], '年代': [], '产地': [], '类别': [], '语言': [], '字幕': [], '上映日期': [], '豆瓣评分': [], '视频尺寸': [], '文件大小': [],
'片长': [], '导演': [], '链接': []}
for i in result:
url1.append(domain + i.group('inner'))
# print(url1)
for i in url1:
resp = requests.get(url=i)
resp.encoding = 'gb2312'
# print(resp.text)
result = obj3.finditer(resp.text)
resp.close()
for j in result:
# print(j.group('name'))
dit['片名'].append(j.group('name'))
dit['年代'].append(j.group('year'))
dit['产地'].append(j.group('address'))
dit['类别'].append(j.group('category'))
dit['语言'].append(j.group('lang'))
dit['字幕'].append(j.group('subtitle'))
dit['上映日期'].append(j.group('time'))
dit['豆瓣评分'].append(j.group('db_score'))
dit['视频尺寸'].append(j.group('size'))
dit['文件大小'].append(j.group('pang_size'))
dit['片长'].append(j.group('long'))
dit['导演'].append(j.group('director'))
dit['链接'].append(j.group('url'))
print(dit)
df = pd.DataFrame(dit)
df.to_csv('dytt.csv',encoding='utf-8-sig')
print('over')
2、bs4模块
安装模块:pip install bs4
2.1.爬取菜价
# -*- coding = utf-8 -*-
# @Time : 2021/6/9 16:16
# @File : 9.bs4模块.py
# @Software: PyCharm
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml'
resp = requests.get(url=url)
# print(resp.text)
page = BeautifulSoup(resp.text, 'html.parser') # 'html.parser'指定html解析器
# find(标签,属性) 找第一个
# find_all(标签,属性) 找全部
# table = page.find('table',class_="hq_table")
table = page.find('table', attrs={'class': 'hq_table'})
# print(table)
trs = table.find_all('tr')[1:]
# print(trs)
dit = {'品名': [], '最低价': [], '平均价': [], '最高价': [], '规格': [], '单位': [], '发布日期': []}
for i in trs:
tds = i.find_all('td')
# print(tds)
dit['品名'].append(tds[0].text)
dit['最低价'].append(tds[1].text)
dit['平均价'].append(tds[2].text)
dit['最高价'].append(tds[3].text)
dit['规格'].append(tds[4].text)
dit['单位'].append(tds[5].text)
dit['发布日期'].append(tds[6].text)
df = pd.DataFrame(dit)
df.to_csv('菜价.csv', encoding='utf-8-sig')
resp.close()
2.2爬取50页菜价
# -*- coding = utf-8 -*-
# @Time : 2021/6/9 16:51
# @File : 10.bs4模块1.py
# @Software: PyCharm
from bs4 import BeautifulSoup
import requests
import pandas as pd
pag = 1
dit = {'品名': [], '最低价': [], '平均价': [], '最高价': [], '规格': [], '单位': [], '发布日期': []}
for num in range(1, 51):
url = f'http://www.xinfadi.com.cn/marketanalysis/0/list/{pag}.shtml'
pag += 1
resp = requests.get(url=url)
# print(resp.text)
page = BeautifulSoup(resp.text, 'html.parser') # 'html.parser'指定html解析器
# find(标签,属性) 找第一个
# find_all(标签,属性) 找全部
# table = page.find('table',class_="hq_table")
table = page.find('table', attrs={'class': 'hq_table'})
# print(table)
trs = table.find_all('tr')[1:]
# print(trs)
for i in trs:
tds = i.find_all('td')
# print(tds)
dit['品名'].append(tds[0].text)
dit['最低价'].append(tds[1].text)
dit['平均价'].append(tds[2].text)
dit['最高价'].append(tds[3].text)
dit['规格'].append(tds[4].text)
dit['单位'].append(tds[5].text)
dit['发布日期'].append(tds[6].text)
df = pd.DataFrame(dit)
df.to_csv('菜价50页.csv', encoding='utf-8-sig')
resp.close()
2.3.优美图库图片
# -*- coding = utf-8 -*-
# @Time : 2021/6/9 18:43
# @File : 11.bs4模块2.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup
import os
link = os.getcwd()
path = os.path.join(link,'图片')
if not os.path.exists(path): # 判断目录是否存在
os.mkdir(path)
os.chdir(path)
url = 'https://www.umei.net/bizhitupian/weimeibizhi' # 唯美图片页面
url1 = 'https://www.umei.net' # 后面用于拼接真正的图片链接
resp = requests.get(url=url)
resp.encoding = 'utf-8' # 解决乱码
page = BeautifulSoup(resp.text, 'html.parser')
resp.close()
div = page.find('div', attrs={'class': 'TypeList'}) # 查找div标签且class=‘TypeList’
alist = div.find_all('a') # 查找所有的a标签
for i in alist: # 遍历所有a标签
page_resp = requests.get(url1 + i.get('href')) # 获取a标签中的href并和url1拼接
page1 = BeautifulSoup(page_resp.text, 'html.parser') # 对从新url获取的数据处理
page_resp.close() # 关闭链接
page1 = page1.find('div', attrs={'class': 'ImageBody'})
img_src = page1.find('img').get('src') # 获取img标签中src的数据
# print(page1)、
img_resp = requests.get(img_src) # 获取图片页面
img =img_resp.content # 拿到图片的二进制
img_name = img_src.split('/')[-1]
# print(img_name)
img_resp.close()
with open(img_name,'wb') as f:
f.write(img)
print('over!')
2.4.爬取多页优美图库图片
# -*- coding = utf-8 -*-
# @Time : 2021/6/9 19:59
# @File : 12.bs4模块3.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup
import os
link = os.getcwd()
path = os.path.join(link, '图片')
if not os.path.exists(path): # 判断目录是否存在
os.mkdir(path)
os.chdir(path)
url0 = 'https://www.umei.net/bizhitupian/weimeibizhi' # 唯美图片页面
url1 = 'https://www.umei.net' # 后面用于拼接真正的图片链接
for num in range(1, 21): # 爬取20页
url = url0
if num != 1:
url = url + '/' + f'index_{num}.htm'
resp = requests.get(url=url)
resp.encoding = 'utf-8' # 解决乱码
page = BeautifulSoup(resp.text, 'html.parser')
resp.close()
div = page.find('div', attrs={'class': 'TypeList'}) # 查找div标签且class=‘TypeList’
alist = div.find_all('a') # 查找所有的a标签
for i in alist: # 遍历所有a标签
page_resp = requests.get(url1 + i.get('href')) # 获取a标签中的href并和url1拼接
page1 = BeautifulSoup(page_resp.text, 'html.parser') # 对从新url获取的数据处理
page_resp.close() # 关闭链接
page1 = page1.find('div', attrs={'class': 'ImageBody'})
img_src = page1.find('img').get('src') # 获取img标签中src的数据
# print(page1)、
img_resp = requests.get(img_src) # 获取图片页面
img = img_resp.content # 拿到图片的二进制
img_name = img_src.split('/')[-1]
# print(img_name)
img_resp.close()
with open(img_name, 'wb') as f:
f.write(img)
print('下载完成---------' + img_name)
print('over!')
四、xpath解析
xpath是在XML文档中搜索内容的一门语言
html是xml的子集
安装lxml模块
pip install lxml
3.xpath的基本使用
# -*- coding = utf-8 -*-
# @Time : 2021/6/10 15:35
# @File : 13.xpath解析.py
# @Software: PyCharm
from lxml import etree
xml = """
<book>
<id>1</id>
<name>野花遍地香</name>
<price>1.23</price>
<nick>臭豆腐</nick>
<author>
<nick id="10086">周大强</nick>
<nick id="10010">周芷若</nick>
<nick class="joy">周杰伦</nick>
<nick class="jolin">蔡依林</nick>
<div>
<nick>热热1</nick>
</div>
</author>
<partner>
<nick id="pprc">胖胖陈</nick>
<nick id="ppbc">胖胖不陈</nick>
</partner>
</book>
"""
tree = etree.XML(xml)
# result = tree.xpath('/book') # /表示层级关系,第一个/表示根节点
# result = tree.xpath('/book/name/')
# result = tree.xpath('/book/name/text()') # 获取book下name下的内容,text()表示获取内容
# result = tree.xpath('/book/author/nick/text()')
xml = """
<book>
<id>1</id>
<name>野花遍地香</name>
<price>1.23</price>
<nick>臭豆腐</nick>
<author>
<nick id="10086">周大强</nick>
<nick id="10010">周芷若</nick>
<nick class="joy">周杰伦</nick>
<nick class="jolin">蔡依林</nick>
<div>
<nick>热热1</nick>
</div>
<div>
<nick>热热2</nick>
<div>
<nick>热热3</nick>
</div>
</div>
</author>
<partner>
<nick id="pprc">胖胖陈</nick>
<nick id="ppbc">胖胖不陈</nick>
</partner>
</book>
"""
tree = etree.XML(xml)
result = tree.xpath('/book/author//nick/text()') # author下的所有nick的内容,//后代
xml = """
<book>
<id>1</id>
<name>野花遍地香</name>
<price>1.23</price>
<nick>臭豆腐</nick>
<author>
<nick id="10086">周大强</nick>
<nick id="10010">周芷若</nick>
<nick class="joy">周杰伦</nick>
<nick class="jolin">蔡依林</nick>
<div>
<nick>热热1</nick>
</div>
<span>
<nick>热热2</nick>
</span>
</author>
<partner>
<nick id="pprc">胖胖陈</nick>
<nick id="ppbc">胖胖不陈</nick>
</partner>
</book>
"""
tree = etree.XML(xml)
# result = tree.xpath('/book/author/*/nick/text()') # *代表任意的,通配符
result = tree.xpath('/book//*/nick/text()') # 找出所有nick
print(result)
from lxml import etree
tree = etree.parse('./网页/b.html')
result = tree.xpath('/html/body/ul/li[1]/a/text()') # 获取第一个li标签下a的值
result = tree.xpath('/html/body/ol/li/a[@href="dapao"]/text()') # 获取a标签href值为大炮的,属性的筛选
ol_li_list = tree.xpath('/html/body/ol/li')
for i in ol_li_list:
result = i.xpath('./a/text()') # 相对路径
print(result)
result = i.xpath('./a/@href') # 获取a标签下href的值
print(result)
print(tree.xpath('/html/body/ul/li/a/@href')) # 获取a标签下href的值
3.1.用xpath爬取猪八戒网站信息
# -*- coding = utf-8 -*-
# @Time : 2021/6/10 20:52
# @File : 14.xpath解析2.py
# @Software: PyCharm
import requests
from lxml import etree
import pandas as pd
url = 'https://hangzhou.zbj.com/search/f/?type=new&kw=saas'
resp = requests.get(url=url)
# print(resp.text)
html = etree.HTML(resp.text)
divs = html.xpath('/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div')
dit = {'标题': [], '价格': [], '店名': [], '地址': []}
for i in divs:
price = i.xpath('./div/div/a[1]/div[2]/div[1]/span[1]/text()')
if len(price) > 0:
price = price[0].strip('¥')
title = 'saas'.join(i.xpath('./div/div/a[1]/div[2]/div[2]/p/text()'))
name = i.xpath('./div/div/a[2]/div[1]/p[1]/text()')
if len(name) > 0:
name = name[1].strip('¥')
add = i.xpath('./div/div/a[2]/div[1]/div/span/text()')
if len(add) > 0:
add = add[0]
dit['标题'].append(title)
dit['价格'].append(price)
dit['店名'].append(name)
dit['地址'].append(add)
df = pd.DataFrame(dit)
df.to_csv('猪八戒.csv',encoding='utf-8-sig')
六、requests进阶

1.模拟用户登录
# -*- coding = utf-8 -*-
# @Time : 2021/6/11 15:40
# @File : 16.模拟用户登录cookie.py
# @Software: PyCharm
import requests
# 会话
# requests.session():维持会话,可以让我们在跨请求时保存某些参数
session = requests.session() # 实例化session
# 设置登录的账号密码
# data = {
# 'loginName': '19967338838',
# 'password': 'HHH123456'
# }
# 登录
# url = 'https://passport.17k.com/ck/user/login' # 目标URL
# resp = session.post(url, data=data) # 发送请求
# print(resp.text) # 查看请求数据
# print(resp.cookies) # 看cookies
# 方法1:利用会话,获取页面数据,session会携带cookie
# resp = session.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919')
# print(resp.json())
# 方法2:直接指定页面url和cookie
resp = requests.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919',headers={
'Cookie': 'GUID=0fe65282-2b49-4422-bb2a-ad91ac7798c1; sajssdk_2015_cross_new_user=1; c_channel=0; c_csc=web; Hm_lvt_9793f42b498361373512340937deb2a0=1623403531; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F11%252F51%252F02%252F77610251.jpg-88x88%253Fv%253D1623397074000%26id%3D77610251%26nickname%3D%25E9%259D%2592%25E8%25A1%25AB%25E8%2590%25BD%25E6%258B%2593R%26e%3D1638974334%26s%3D1ad4e184068d6fcb; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2277610251%22%2C%22%24device_id%22%3A%22179f9fec157b99-0f0d7871cdecd6-f7f1939-1350728-179f9fec158c5d%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%220fe65282-2b49-4422-bb2a-ad91ac7798c1%22%7D'
})
print(resp.json())
2.处理防盗链,爬取梨视频文章中的视频
# -*- coding = utf-8 -*-
# @Time : 2021/6/12 15:18
# @File : 17.梨视频-防盗链处理.py
# @Software: PyCharm
# 本脚本用于爬取梨视频的视频,输入某个文章页面的链接,等待片刻,即在当前目录下创建’视频‘文件夹并把视频下载到本地。
import requests
import os
link = os.getcwd()
path = os.path.join(link, '视频')
if not os.path.exists(path): # 判断目录是否存在
os.mkdir(path)
os.chdir(path)
url = input('请输入要下载的文章视频链接:')
# url = 'https://www.pearvideo.com/video_1732010' # 带有contId的链接
countId = url.split('_')[-1]
videoStatus = f'https://www.pearvideo.com/videoStatus.jsp?contId={countId}&mrd=0.1269552532349294' # 抓包链接
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36',
'Referer': url # 处理防盗链:'Referer': 'https://www.pearvideo.com/video_1732010'为上级链接
}
resp = requests.get(videoStatus, headers=headers)
systemTime = resp.json()['systemTime'] # 获取时间戳
videoUrl = resp.json()['videoInfo']['videos']['srcUrl'] # 获取带有时间戳的视频链接
# print(videoUrl)
# print(systemTime)
videoUrl = videoUrl.replace(systemTime, f'cont-{countId}') # 将时间戳替换为conId,获取真正的视频连接
videoName = videoUrl.split('/')[-1]
videoResp = requests.get(videoUrl) # 获取视频链接数据
video = videoResp.content # 将视频链接数据转为二进制
with open(videoName, 'wb') as f:
f.write(video)
print('over!')
七、给爬虫提速

1.多线程
进程是资源单位,每一个进程至少要有一个线程
线程是执行单位
启动每一个程序默认都有一个主线程
# 单线程
# def func():
# for i in range(1000):
# print('func', i)
#
#
# if __name__ == '__main__':
# func()
# for i in range(1000):
# print('main', i)
# 多线程
# from threading import Thread
#
# def func():
# for i in range(1000):
# print('func', i)
#
#
# if __name__ == '__main__':
# t = Thread(target=func) # 创建线程并指定任务
# t.start() # 多线程状态为可以开始工作状态,具体的执行时间为CPU决定
# for i in range(1000):
# print('main', i)
# 多线程2
# from threading import Thread
#
#
# class MyThread(Thread):
# def run(self): # 从写run方法
# for i in range(1000):
# print('子线程', i)
#
#
# if __name__ == '__main__':
# t = MyThread() # 创建线程并指定任务
# t.start() # 当调用start方法时,默认会执行run方法
# for i in range(1000):
# print('主线程', i)
# 多线程传参1
# from threading import Thread
#
#
# def func(num):
# for i in range(num):
# print('func', i)
#
#
# if __name__ == '__main__':
# t = Thread(target=func,args=(10000,)) # 创建线程并指定任务,传的参数必须是元组
# t.start() # 多线程状态为可以开始工作状态,具体的执行时间为CPU决定
# for i in range(10000):
# print('main', i)
# 多线程传参2
from threading import Thread
class MyThread(Thread):
def __init__(self,num):
Thread.__init__(self) # 继承父类构造方法
self.num = num
def run(self): # 从写run方法
for i in range(self.num):
print('子线程', i)
if __name__ == '__main__':
t = MyThread(10000) # 创建线程并指定任务
t.start() # 当调用start方法时,默认会执行run方法
for i in range(10000):
print('主线程', i)
2.多进程
from multiprocessing import Process
def func():
for i in range(100000):
print('子进程', i)
if __name__ == '__main__':
p = Process(target=func)
p.start()
for i in range(100000):
print('主进程', i)
3.线程池和进程池
一次性开辟一些线程,我们用户直接给线程提交任务,线程任务的调度由线程池来完成
# -*- coding = utf-8 -*-
# @Time : 2021/6/14 13:33
# @File : 23.线程池实战.py
# @Software: PyCharm
from lxml import etree
import requests
import csv
from concurrent.futures import ThreadPoolExecutor
import time
start = time.time()
f = open('多线程_菜价.csv', 'w', encoding='utf-8-sig', newline='')
csv_write = csv.writer(f)
csv_write.writerow(['品名', '最低价', '平均价', '最高价', '规格', '单位', '发布日期']) # 表头
def func(num):
url = f'http://www.xinfadi.com.cn/marketanalysis/0/list/{num}.shtml'
resp = requests.get(url=url)
html = etree.HTML(resp.text)
table = html.xpath('/html/body/div[2]/div[4]/div[1]/table')[0]
trs = table.xpath('./tr[position()>1]') # 去除表头
# print(len(trs))
for tr in trs:
txt = tr.xpath('./td/text()')
txt = [i.replace('//', '').replace('\\', '') for i in txt]
csv_write.writerow(txt)
print(url, '下载完毕')
if __name__ == '__main__':
with ThreadPoolExecutor(50) as t:
for i in range(1, 14870):
t.submit(func, num=i)
end = time.time()
print(end - start)
- 利用多线程爬取北京新发地菜价表格速度快了很多倍,不停的爬取页面会导致服务器高度负载,导致后面连网页也访问不了,导致爬取速度下降。
4.协程
# -*- coding = utf-8 -*-
# @Time : 2021/6/15 15:22
# @File : 24.协程.py
# @Software: PyCharm
import time
# def func():
# print('我爱黎明')
# time.sleep(3) # 让当前的线程处于阻塞状态,CPU是不为我工作
# print('我真的爱黎明')
#
#
# if __name__ == '__main__':
# func()
# input() 等在用户输入信息时,程序属于阻塞状态
# requests.get() 在我们请求一个url时,会等待服务器返回信息,在此阶段我们也是阻塞状态
# 一般情况下,当程序属于io状态时,都是阻塞状态
# 协程:当程序遇见了io操作的时候,会选择性的切换到其他任务上。
# 在微观上是一个任务一个任务的进行切换,切换条件一般就是io操作
# 在宏观上我们能看到的就是多个任务一起在执行
# 多任务异步操作
# 上方所讲的都是在单线程的条件下
# python编写协程
import asyncio
# async def func(): # 协程函数
# print('你好,世界!')
#
# if __name__ == '__main__':
# input('请输入你的姓名')
# # func() # 此时的函数是异步协程函数,此时函数执行得到的是一个协程对象
# g = func()
# # print(g)
# asyncio.run(g) # 运行协程对象,协程对象运行需要asyncio模块支持
# 一般写法
# async def func1():
# print('我叫吴彦祖')
# # time.sleep(3) # 当程序出现了同步操作的时候,异步操作就中断了
# await asyncio.sleep(3) # await挂起,异步操作
# print('我叫刘德华')
#
#
# async def func2():
# print('我叫吴彦祖')
# # time.sleep(3)
# await asyncio.sleep(2)
# print('我叫刘德华')
#
#
# async def func3():
# print('我叫吴彦祖')
# # time.sleep(3)
# await asyncio.sleep(4)
# print('我叫刘德华')
#
#
# if __name__ == '__main__':
# f1 = func1()
# f2 = func2()
# f3 = func3()
# tasks = [f1, f2, f3]
# start = time.time()
# asyncio.run(asyncio.wait(tasks))
# end = time.time()
# print(end-start)
# 推荐写法
async def func1():
print('我叫吴彦祖')
await asyncio.sleep(3) # await挂起,异步操作
print('我叫刘德华')
async def func2():
print('我叫吴彦祖')
await asyncio.sleep(2)
print('我叫刘德华')
async def func3():
print('我叫吴彦祖')
await asyncio.sleep(4)
print('我叫刘德华')
async def main():
# 写法1
# f = func1()
# await f # 一般await挂起操作写在协程对象前面
# 写法2(推荐)
tasks = [func1(), func2(), func3()]
# tasks = [asyncio.create_task(func1()), asyncio.create_task(func2()), asyncio.create_task(func3())] # python3.8之后用这种
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
5.aiohttp模块的使用
安装pip install aiohttp
# -*- coding = utf-8 -*-
# @Time : 2021/6/15 16:18
# @File : 25.aiohttp模块的使用.py
# @Software: PyCharm
import aiohttp
import asyncio
# 要爬取的链接
urls = [
'http://kr.shanghai-jiuxin.com/file/2021/0609/smallc68aab5c9aee1675728ed1965c9a350c.jpg',
'http://kr.shanghai-jiuxin.com/file/2021/0609/smalld962470284e0403159107fe22f1ef561.jpg',
'http://kr.shanghai-jiuxin.com/file/2021/0609/small7b7868d1e911a35b269bde4b8b05dfb8.jpg'
]
async def download(url): # 定义下载函数
async with aiohttp.ClientSession() as session: # request
async with session.get(url) as resp: # resp = requests.get()
name = url.split('/')[-1]
with open(name, 'wb') as f: # 创建文件
f.write(await resp.content.read()) # 读取内容是异步的,需要挂起
print(name, '搞定')
async def main():
tasks = []
for url in urls:
tasks.append(download(url))
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
6.利用协程扒光一部小说
# -*- coding = utf-8 -*-
# @Time : 2021/6/15 16:37
# @File : 26.用协程扒光一部小说.py
# @Software: PyCharm
import requests
from lxml import etree
import os
import time
import asyncio
import aiohttp
import aiofiles
'''
因为网页反爬机制,又因为程序利用协程技术爬取过快,所以很容易被墙,所以此程序仅供参考,没有太大的用处!,还是慢慢单线程爬吧,或者搞个代理池,再或者你有破解反爬的技术。
'''
start = time.time()
link = os.getcwd()
path = os.path.join(link, '小说')
if not os.path.exists(path): # 判断目录是否存在
os.mkdir(path)
os.chdir(path)
url = 'http://book.zongheng.com/showchapter/840978.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
resp = requests.get(url, headers=headers)
# print(resp.text)
html = etree.HTML(resp.text)
urls = html.xpath('/html/body/div[3]/div[2]/div[2]/div/*/li/a/@href') # 获取所有章节链接
# for i in urls:
# print(i)
# print(len(urls))
async def download(href):
time.sleep(1)
async with aiohttp.ClientSession() as session: # requests
async with session.get(href) as resp_href: # resp = requests.get()
resp_href.encoding = 'utf-8'
print(await resp_href.text())
html_href = etree.HTML(await resp_href.text())
# print(html_href)
content = html_href.xpath('/html/body/div[2]/div[3]/div[3]/div/div[5]/p/text()')
print(content)
content[0] = ' ' + content[0] # 解决第一段没有开头没有空2格
content = '\n'.join(content) # 将提取出来的列表变成一整个字符串
# print(content)
name = html_href.xpath('/html/body/div[2]/div[3]/div[3]/div/div[2]/div[2]/text()') # 获取章节名称
content = name[0] + '\n' + content # 在每一章内容的前面都加上章名
async with aiofiles.open(f'{name[0]}.txt', 'w', encoding='utf-8') as f: # 异步写入文件,保存
f.write(content)
print(name[0], '-------下载完成!')
async def main():
tasks = [] # 创建任务列表
for i in urls[4:5]:
print(i)
tasks.append(download(i)) # 将所有的下载任务添加到任务列表
await asyncio.wait(tasks)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
八、爬取一部视频
1.视频网站的工作原理
# <video src="一部视频.mp4"></video><video> # 一般网站放视频
# 用户上传 -> 转码(把视频做处理,2k,108,标清),->切片处理(把单个的文件进行拆分)
# 拖动滚动条直接加载滚动条处的位置
# ==========================
# 需要一个文件记录:1.视频播放顺序,2.视频存放的路径
# M3U8 txt json => 文本
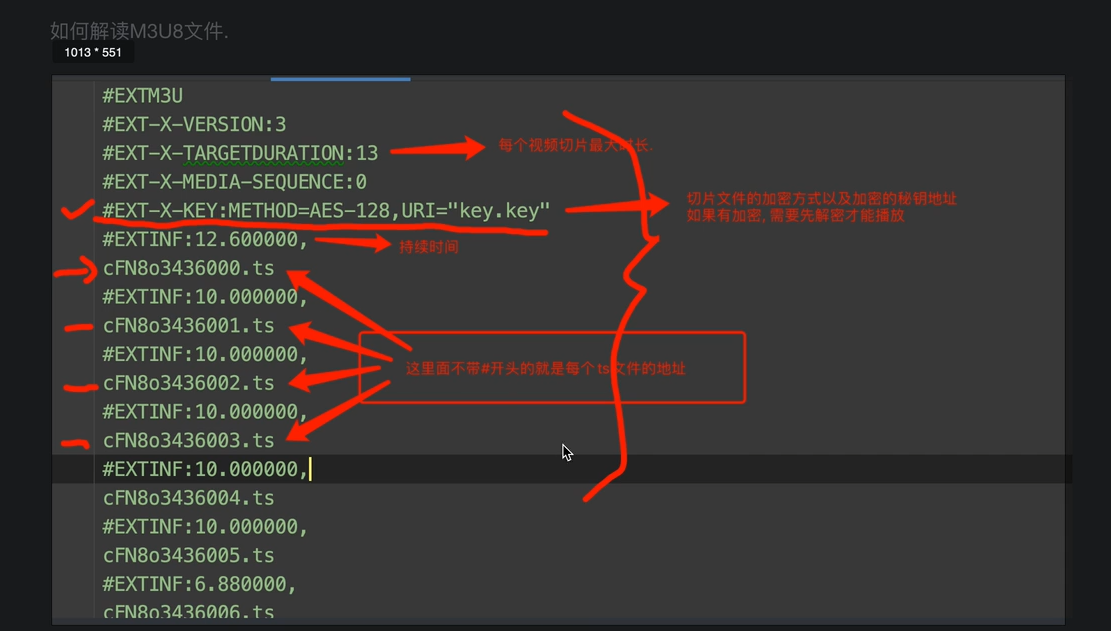
- 爬取视频步骤
- 找到m3u8(各种手段)
- 通过m3u8下载到ts文件
- 可以通过各种手段(不仅是变成手段)把ts文件合并为一个mp4文件。